The Unshakeables podcast from Chase for Business and iHeartMedia's Ruby Studio dives into the unbelievable “What are we gonna do now?” moments that changed everything for small business owners. From mom-and-pop coffee shops to auto-detailing garages, every small business owner knows that the journey is full of the unexpected. A single make-or-break experience can change the course of your business forever. Those who stand firm in their resolve have a special name. We call them The Unshakeabl ...
…
continue reading
תוכן מסופק על ידי O'Reilly Media. כל תוכן הפודקאסטים כולל פרקים, גרפיקה ותיאורי פודקאסטים מועלים ומסופקים ישירות על ידי O'Reilly Media או שותף פלטפורמת הפודקאסט שלהם. אם אתה מאמין שמישהו משתמש ביצירה שלך המוגנת בזכויות יוצרים ללא רשותך, אתה יכול לעקוב אחר התהליך המתואר כאן https://he.player.fm/legal.
דומה לO'Reilly Data Show Podcast
Best Business Podcast (Gold), British Podcast Awards 2023 How do you build a fully electric motorcycle with no compromises on performance? How can we truly experience what the virtual world feels like? What does it take to design the first commercially available flying car? And how do you build a lightsaber? These are some of the questions this podcast answers as we share the moments where digital transforms physical, and meet the brilliant minds behind some of the most innovative products a ...
…
continue reading
Tim Reid (AKA Timbo) interviews the most innovative founders in the world of small business. In this award winning podcast business owners share where their original business idea came from, how they got it to market and the strategies they used that led to their business’s unprecedented growth. Tim Reid's curiosity for what makes business owners tick and his passion for small business success means that every episode is chock full of marketing gold that will help you build that beautiful bu ...
…
continue reading
It didn’t all change in March 2020. Not really. The UK high street has been in the throes of a gradual revolution for decades. From the rise of ecommerce, to the birth of mobile, social commerce, and a growing emphasis on experience, change has been underway for a while. In fact for many, the pandemic has acted as a wake-up call. Digital transformation was no longer a ‘nice to have’ but a matter of survival. Necessity sparked innovation and customers are enjoying more flexibility and conveni ...
…
continue reading
Custom Manufacturing Industry podcast is an entrepreneurship and motivational podcast on all platforms, hosted by Aaron Clippinger. Being CEO of multiple companies including the signage industry and the software industry, Aaron has over 20 years of consulting and business management. His software has grown internationally and with over a billion dollars annually going through the software. Using his Accounting degree, Aaron will be talking about his organizational ways to get things done. Hi ...
…
continue reading
The Knowledge at Wharton Network Acast feed serves as a curated showcase highlighting the best content from our podcast collection. Each week, we feature one standout episode from each show in the Wharton Podcast Network, giving listeners a comprehensive sample of our diverse business and academic content. This rotating selection allows audiences to discover new shows within our network while experiencing the depth and variety of Wharton's thought leadership across different topics and forma ...
…
continue reading
Alessandro Bogliari, CEO and Co-Founder of The Influencer Marketing Factory, a global influencer marketing agency, talks with great guests about influencer marketing, social media, the creator economy, social commerce and much more.
…
continue reading
Where startup founders raise millions and listeners can invest. Host Josh Muccio takes listeners behind closed-doors and into the room where deals are made. Part of the Vox Media Podcast Network.
…
continue reading
Call them changemakers. Call them rule breakers. We call them Redefiners. And in this provocative podcast, we explore how daring leaders from across industries and around the globe are redefining their organizations—and themselves—to create extraordinary impact in today’s rapidly changing world. In each episode, Russell Reynolds Associates Leadership Advisor Hoda Tahoun and former CEO Clarke Murphy host engaging, purposeful conversations with leaders in and out of the business world who shar ...
…
continue reading
x.com/naval
…
continue reading
Player FM - אפליקציית פודקאסט
התחל במצב לא מקוון עם האפליקציה Player FM !
התחל במצב לא מקוון עם האפליקציה Player FM !

))
Labeling, transforming, and structuring training data sets for machine learning
Manage episode 248276630 series 61203
תוכן מסופק על ידי O'Reilly Media. כל תוכן הפודקאסטים כולל פרקים, גרפיקה ותיאורי פודקאסטים מועלים ומסופקים ישירות על ידי O'Reilly Media או שותף פלטפורמת הפודקאסט שלהם. אם אתה מאמין שמישהו משתמש ביצירה שלך המוגנת בזכויות יוצרים ללא רשותך, אתה יכול לעקוב אחר התהליך המתואר כאן https://he.player.fm/legal.
In this episode of the Data Show, I speak with Alex Ratner, project lead for Stanford’s Snorkel open source project; Ratner also recently garnered a faculty position at the University of Washington and is currently working on a company supporting and extending the Snorkel project. Snorkel is a framework for building and managing training data. Based on our survey from earlier this year, labeled data remains a key bottleneck for organizations building machine learning applications and services.
Ratner was a guest on the podcast a little over two years ago when Snorkel was a relatively new project. Since then, Snorkel has added more features, expanded into computer vision use cases, and now boasts many users, including Google, Intel, IBM, and other organizations. Along with his thesis advisor professor Chris Ré of Stanford, Ratner and his collaborators have long championed the importance of building tools aimed squarely at helping teams build and manage training data. With today’s release of Snorkel version 0.9, we are a step closer to having a framework that enables the programmatic creation of training data sets.
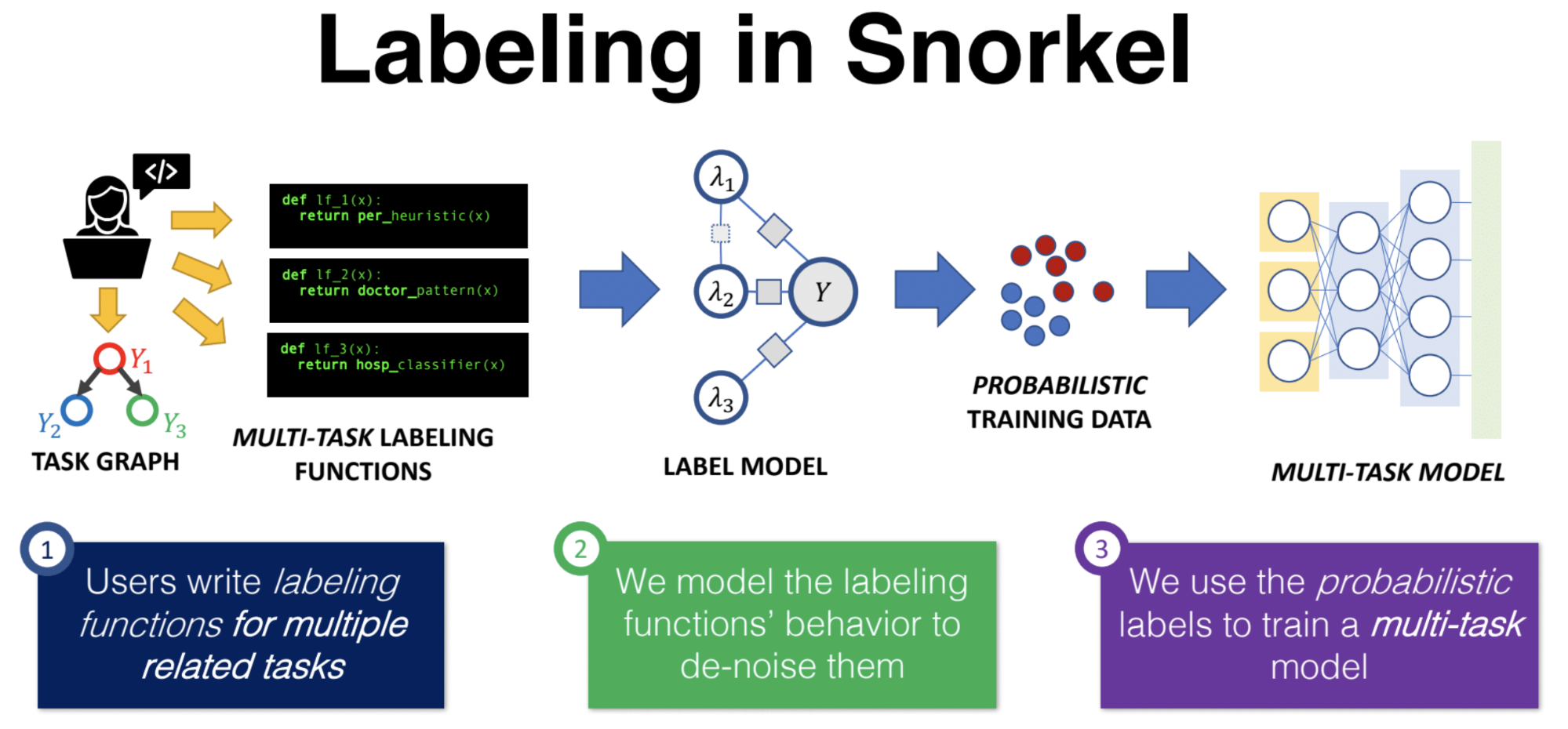
We had a great conversation spanning many topics, including:
- Why he and his collaborators decided to focus on “data programming” and tools for building and managing training data.
- A tour through Snorkel, including its target users and key components.
- What’s in the newly released version (v 0.9) of Snorkel.
- The number of Snorkel’s users has grown quite a bit since we last spoke, so we went through some of the common use cases for the project.
- Data lineage, AutoML, and end-to-end automation of machine learning pipelines.
- Holoclean and other projects focused on data quality and data programming.
- The need for tools that can ease the transition from raw data to derived data (e.g., entities), insights, and even knowledge.
Related resources:
- “Product management in the machine learning era”: A tutorial at the Artificial Intelligence Conference in San Jose, September 9-12, 2019.
- Chris Ré: “Software 2.0 and Snorkel”
- Alex Ratner: “Creating large training data sets quickly”
- Ihab Ilyas and Ben Lorica on “The quest for high-quality data”
- Roger Chen: “Acquiring and sharing high-quality data”
- Jeff Jonas on “Real-time entity resolution made accessible”
- “Data collection and data markets in the age of privacy and machine learning”
168 פרקים
Manage episode 248276630 series 61203
תוכן מסופק על ידי O'Reilly Media. כל תוכן הפודקאסטים כולל פרקים, גרפיקה ותיאורי פודקאסטים מועלים ומסופקים ישירות על ידי O'Reilly Media או שותף פלטפורמת הפודקאסט שלהם. אם אתה מאמין שמישהו משתמש ביצירה שלך המוגנת בזכויות יוצרים ללא רשותך, אתה יכול לעקוב אחר התהליך המתואר כאן https://he.player.fm/legal.
In this episode of the Data Show, I speak with Alex Ratner, project lead for Stanford’s Snorkel open source project; Ratner also recently garnered a faculty position at the University of Washington and is currently working on a company supporting and extending the Snorkel project. Snorkel is a framework for building and managing training data. Based on our survey from earlier this year, labeled data remains a key bottleneck for organizations building machine learning applications and services.
Ratner was a guest on the podcast a little over two years ago when Snorkel was a relatively new project. Since then, Snorkel has added more features, expanded into computer vision use cases, and now boasts many users, including Google, Intel, IBM, and other organizations. Along with his thesis advisor professor Chris Ré of Stanford, Ratner and his collaborators have long championed the importance of building tools aimed squarely at helping teams build and manage training data. With today’s release of Snorkel version 0.9, we are a step closer to having a framework that enables the programmatic creation of training data sets.
We had a great conversation spanning many topics, including:
- Why he and his collaborators decided to focus on “data programming” and tools for building and managing training data.
- A tour through Snorkel, including its target users and key components.
- What’s in the newly released version (v 0.9) of Snorkel.
- The number of Snorkel’s users has grown quite a bit since we last spoke, so we went through some of the common use cases for the project.
- Data lineage, AutoML, and end-to-end automation of machine learning pipelines.
- Holoclean and other projects focused on data quality and data programming.
- The need for tools that can ease the transition from raw data to derived data (e.g., entities), insights, and even knowledge.
Related resources:
- “Product management in the machine learning era”: A tutorial at the Artificial Intelligence Conference in San Jose, September 9-12, 2019.
- Chris Ré: “Software 2.0 and Snorkel”
- Alex Ratner: “Creating large training data sets quickly”
- Ihab Ilyas and Ben Lorica on “The quest for high-quality data”
- Roger Chen: “Acquiring and sharing high-quality data”
- Jeff Jonas on “Real-time entity resolution made accessible”
- “Data collection and data markets in the age of privacy and machine learning”
168 פרקים
כל הפרקים
×ברוכים הבאים אל Player FM!
Player FM סורק את האינטרנט עבור פודקאסטים באיכות גבוהה בשבילכם כדי שתהנו מהם כרגע. זה יישום הפודקאסט הטוב ביותר והוא עובד על אנדרואיד, iPhone ואינטרנט. הירשמו לסנכרון מנויים במכשירים שונים.
דומה לO'Reilly Data Show Podcast
The Unshakeables podcast from Chase for Business and iHeartMedia's Ruby Studio dives into the unbelievable “What are we gonna do now?” moments that changed everything for small business owners. From mom-and-pop coffee shops to auto-detailing garages, every small business owner knows that the journey is full of the unexpected. A single make-or-break experience can change the course of your business forever. Those who stand firm in their resolve have a special name. We call them The Unshakeabl ...
…
continue reading
Best Business Podcast (Gold), British Podcast Awards 2023 How do you build a fully electric motorcycle with no compromises on performance? How can we truly experience what the virtual world feels like? What does it take to design the first commercially available flying car? And how do you build a lightsaber? These are some of the questions this podcast answers as we share the moments where digital transforms physical, and meet the brilliant minds behind some of the most innovative products a ...
…
continue reading
Tim Reid (AKA Timbo) interviews the most innovative founders in the world of small business. In this award winning podcast business owners share where their original business idea came from, how they got it to market and the strategies they used that led to their business’s unprecedented growth. Tim Reid's curiosity for what makes business owners tick and his passion for small business success means that every episode is chock full of marketing gold that will help you build that beautiful bu ...
…
continue reading
It didn’t all change in March 2020. Not really. The UK high street has been in the throes of a gradual revolution for decades. From the rise of ecommerce, to the birth of mobile, social commerce, and a growing emphasis on experience, change has been underway for a while. In fact for many, the pandemic has acted as a wake-up call. Digital transformation was no longer a ‘nice to have’ but a matter of survival. Necessity sparked innovation and customers are enjoying more flexibility and conveni ...
…
continue reading
Custom Manufacturing Industry podcast is an entrepreneurship and motivational podcast on all platforms, hosted by Aaron Clippinger. Being CEO of multiple companies including the signage industry and the software industry, Aaron has over 20 years of consulting and business management. His software has grown internationally and with over a billion dollars annually going through the software. Using his Accounting degree, Aaron will be talking about his organizational ways to get things done. Hi ...
…
continue reading
The Knowledge at Wharton Network Acast feed serves as a curated showcase highlighting the best content from our podcast collection. Each week, we feature one standout episode from each show in the Wharton Podcast Network, giving listeners a comprehensive sample of our diverse business and academic content. This rotating selection allows audiences to discover new shows within our network while experiencing the depth and variety of Wharton's thought leadership across different topics and forma ...
…
continue reading
Alessandro Bogliari, CEO and Co-Founder of The Influencer Marketing Factory, a global influencer marketing agency, talks with great guests about influencer marketing, social media, the creator economy, social commerce and much more.
…
continue reading
Where startup founders raise millions and listeners can invest. Host Josh Muccio takes listeners behind closed-doors and into the room where deals are made. Part of the Vox Media Podcast Network.
…
continue reading
Call them changemakers. Call them rule breakers. We call them Redefiners. And in this provocative podcast, we explore how daring leaders from across industries and around the globe are redefining their organizations—and themselves—to create extraordinary impact in today’s rapidly changing world. In each episode, Russell Reynolds Associates Leadership Advisor Hoda Tahoun and former CEO Clarke Murphy host engaging, purposeful conversations with leaders in and out of the business world who shar ...
…
continue reading
x.com/naval
…
continue reading
Player FM - אפליקציית פודקאסט
התחל במצב לא מקוון עם האפליקציה Player FM !
התחל במצב לא מקוון עם האפליקציה Player FM !



